The hidden cost of “almost correct” addresses
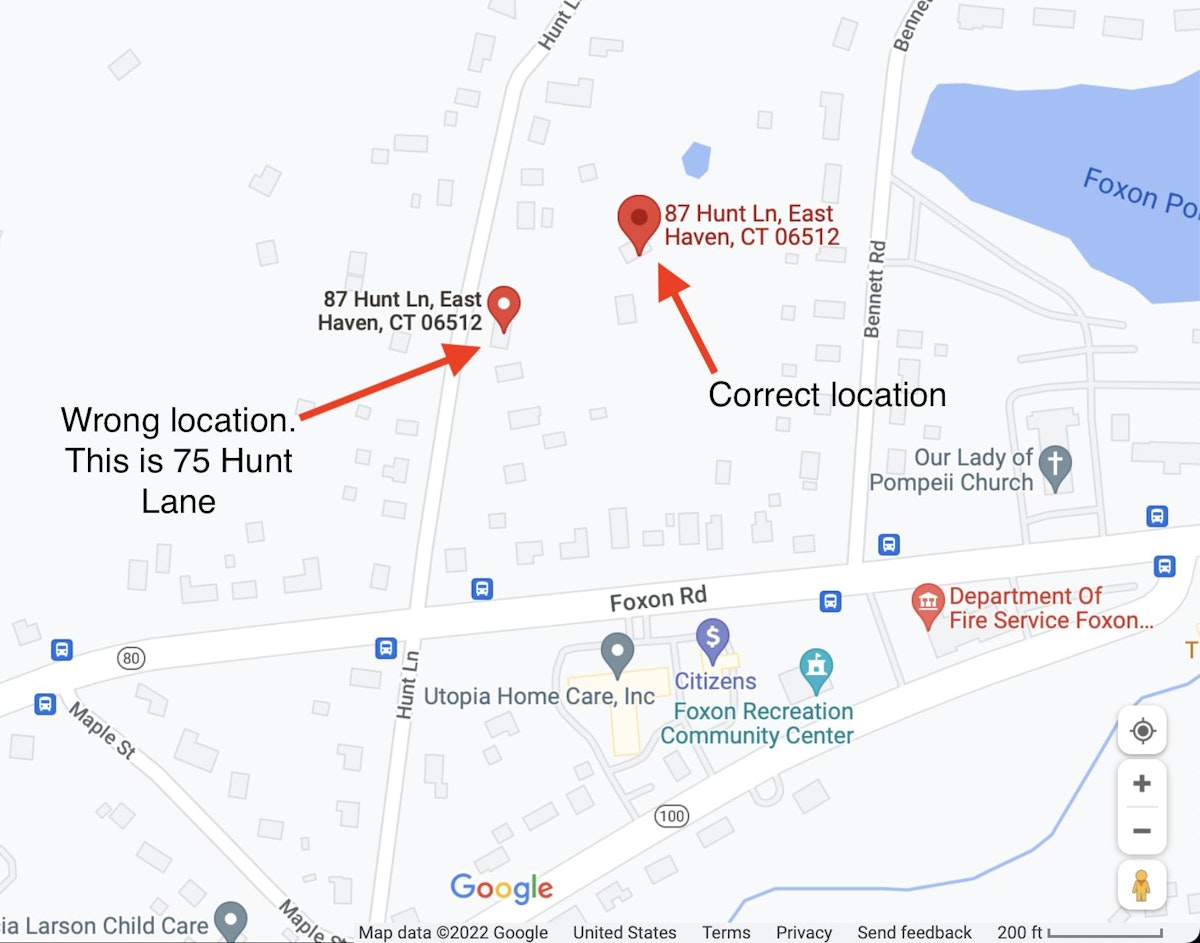
When businesses think about location data quality issues, they often imagine obvious errors: missing addresses, incorrect postal codes, or locations that simply do not exist. These problems are relatively easy to identify and correct. However, one of the biggest challenges facing modern supply chains is far less visible—the problem of "almost correct" addresses.
An address that is mostly accurate may appear harmless. After all, if the city, street, and postal code are nearly correct, surely the impact on operations must be minimal. In reality, even small inconsistencies in location data can create significant operational inefficiencies, increase costs, and reduce visibility across the supply chain.
As logistics networks become more complex and increasingly dependent on automation, businesses can no longer afford to overlook these seemingly minor errors. In this blog post, we will explore why "almost correct" addresses represent one of the most underestimated challenges in modern logistics and why organizations should take them seriously.
What Does "Almost Correct" Actually Mean?
An "almost correct" address is a location record that contains enough information to appear valid but includes subtle inaccuracies, inconsistencies, or missing details.
Examples include:
- Incorrect building numbers
- Missing suite, floor, or unit information
- Alternative street abbreviations
- Slight spelling variations
- Outdated postal codes
- Inconsistent formatting across systems
- Missing geographic coordinates
- Different naming conventions for the same facility
Consider the following examples:
- "Industrial Park 12, Building A"
- "Industrial Pk. 12, Bldg A"
- "Industrial Park No. 12, Warehouse A"
To a person, these locations may clearly refer to the same destination. However, many enterprise systems treat them as separate records entirely.
The challenge is that these addresses are not obviously wrong. They pass validation checks, enter operational systems, and continue to circulate throughout the supply chain without raising immediate concerns.
Why Small Errors Become Big Problems
In modern supply chains, location data does not exist in isolation. It moves between ERP systems, warehouse management platforms, transportation systems, customer portals, and partner networks.
When an "almost correct" address enters one system, it often propagates to many others. Over time, small inconsistencies multiply, creating duplicate records and conflicting versions of the same location.
What initially appears to be a minor data issue can quickly evolve into operational complexity.
For example:
- Transportation planners may optimize routes using duplicate delivery locations.
- Warehouse systems may maintain separate inventory records for the same facility.
- Reporting systems may generate inaccurate analytics.
- Customer service teams may struggle to identify the correct destination.
- Carriers may experience delays due to incomplete delivery instructions.
Because each individual error appears insignificant, organizations often underestimate the cumulative impact these inaccuracies have on operations.
The Hidden Financial Impact
The cost of "almost correct" addresses rarely appears as a single line item on a financial report. Instead, it manifests as a series of small inefficiencies that accumulate over time.
These hidden costs may include:
- Increased transportation expenses due to inefficient routing
- Failed or delayed deliveries
- Additional fuel consumption
- Higher administrative workloads
- Manual data correction efforts
- Duplicate operational activities
- Reduced productivity
- Customer service costs
- Lost business opportunities
For organizations managing thousands or millions of shipments annually, even a small percentage of location errors can result in substantial financial consequences.
The challenge is that businesses often attribute these costs to operational complexity rather than recognizing poor location data as the underlying cause.
Why Automation Makes the Problem Worse
Many organizations assume that increased automation will solve data quality problems. In reality, automation often amplifies existing inaccuracies.
Automated systems depend on accurate and consistent location data to function effectively. Route optimization software, warehouse automation, predictive analytics, and artificial intelligence systems all rely on trusted inputs.
When these systems encounter "almost correct" addresses, they do exactly what they were designed to do—they process them.
Unfortunately, processing incorrect information faster does not eliminate the problem. It simply allows errors to spread more efficiently throughout the organization.
As businesses continue investing in digital transformation, the quality of their location data becomes increasingly important. Poor data can undermine even the most advanced technologies.
The Visibility Problem
Perhaps the most dangerous aspect of "almost correct" addresses is that they often remain invisible.
Unlike completely invalid addresses, which typically generate immediate errors, nearly correct addresses continue moving through operational systems. They may produce occasional exceptions, delays, or inconsistencies, but these problems are rarely traced back to their original source.
As a result, organizations often experience:
- Unexplained operational inefficiencies
- Inconsistent reporting
- Poor forecasting accuracy
- Duplicate records
- Increased exception handling
- Reduced confidence in analytics
Without dedicated location data management processes, businesses may spend years treating the symptoms while never addressing the root cause.
Moving from Validation to Understanding
Traditional data validation methods focus primarily on determining whether an address exists. However, modern supply chains require a deeper understanding of location information.
Businesses increasingly need to answer questions such as:
- Is this location already present in another system?
- Is the address complete enough for operational execution?
- Does this record represent the same physical location as another entry?
- Is additional contextual information required?
- Can this location support automated processes?
Answering these questions requires more than simple validation. It requires intelligent matching, standardization, enrichment, and ongoing data quality management.
Organizations that adopt this approach can significantly reduce operational complexity while improving visibility and efficiency across their supply chains.
Why Businesses Must Address the Problem Now
As supply chains become more global, digital, and interconnected, the cost of poor location data will continue to increase.
Customer expectations for speed and accuracy continue to rise. At the same time, businesses are investing heavily in automation, artificial intelligence, and advanced analytics. None of these initiatives can achieve their full potential without reliable location data.
The organizations that recognize the hidden cost of "almost correct" addresses today will be better positioned to improve operational performance, reduce costs, and build more resilient supply chains for the future.
Ignoring the problem is no longer a sustainable option.
Conclusion
In modern logistics, an address does not need to be completely wrong to create significant operational challenges. In fact, "almost correct" addresses often represent a greater risk because they remain hidden within operational systems for extended periods.
These subtle inaccuracies lead to inefficiencies, increased costs, reduced visibility, and poor decision-making throughout the supply chain. As businesses become increasingly dependent on automation and digital technologies, maintaining high-quality location data has become a strategic necessity.
Organizations that move beyond simple validation and focus on creating accurate, standardized, and context-rich location data will gain a significant competitive advantage.